My other posts
Self-healing ASP.NET Core APIs on Container Apps
Table of contents
Introduction
Monitoring applications in production to ensure they are working fine can be a painful process if it is done manually. There are tools that can be used to send requests to an application on a schedule, such as Azure Application Insight's availability tests, which can be used to generate alerts when the application fails to respond with an expected response code.
For these availability tests to be useful, however, the requests done must test different parts of the system to ensure that the application's dependencies are working, but also that the internal state of the application is the expected. These are typically referred to as health checks, and as the name implies, they allow us to check the health of the application.
In this post, we will look at configuring health checks on an ASP.NET Core API as a first step. Then, we will switch our focus to Azure Container Apps, which is an Azure-managed Kubernetes service, to configure health probes using the health checks configured.
Sample application
Let's consider the simplest ASP.NET Core API possible:
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/hello", () => "Hello!");
app.Run();
This application has just one /hello endpoint. Now, let's add the simplest health check to act as a foundation, using the built-in ASP.NET Core support:
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddHealthChecks();
var app = builder.Build();
app.MapHealthChecks("/ct-healthz");
app.MapGet("/hello", () => "Hello!");
app.Run();
If you run this application and do a GET request (such as through a browser) to the /ct-healthz endpoint, you'll get back a Healthy message. This simple healthcheck is enough to determine whether the application is running or not.
Notice, however, that all healthchecks added to the service collection would be run with this usage of MapHealthChecks, which might not be desired. We will refine this in the next section.
Health probes
Azure Container Apps, through the Kubernetes engine, supports 3 types of health probes. These probes are executed automatically by the engine at pre-defined times to check the health of the application and container.
Using health probes allows the engine to automatically create new containers to replace the ones that have failed the configured thresholds for the health probes.
Startup probe
The first probe that can be configured is the startup probe. This is a special probe that is used to determine if a newly created container has finished starting up successfully or not.
If your API does not need any special startup configuration, it could be enough to define an always healthy check:
builder.Services
.AddHealthChecks()
.AddCheck("startup", check => HealthCheckResult.Healthy(), tags: [ "startup" ]);
Notice the addition of the "startup" tag. This allows you to add an endpoint that only runs this particular check:
app.MapHealthChecks("/ct-healthz/startup", new HealthCheckOptions { Predicate = (check) => check.Tags.Contains("startup") });
At this point, you may be wondering what is the benefit of adding a healthcheck that is always healthy. This gives you two important benefits:
- The healthcheck can only return Healthy if the application is running. If the application crashed, for example, due to a missing environment variable value, this probe could automatically mark the revision as unhealthy.
- Using the same approach as for other health probes allows you to easily extend this to other checks in the future. Besides, as this endpoint returns a static value, it is fast and you do not have to worry about it becoming slow.
Readiness probe
A readiness probe can be defined for applications that have requirements, such as internal processors or external dependencies, to be working correctly before being able to respond to external traffic. An application can define a readiness probe so that Container Apps does not serve traffic to the containers that are not reporting healthy.
Examples healthchecks for this probe include logic run after starting the application, such as loading files or an in-memory cache. You can also add checks for the application being overloaded, like internal processing queues having too many pending messages or critical external services are failing to respond. This allows the container to stop receiving requests for some time, which would hopefully allow the application to recover.
Depending on your application's requirements and the services/libraries you use, you may need to write the healthchecks yourself, but in many cases, the AspNetCore.Diagnostics.HealthChecks library can be used.
For example, the HealthChecks.Azure.Storage.Queues package provides a healthcheck that ensures the connection to the queue works and that the queue exists. The healthcheck could be injected like this:
builder.Services
.AddHealthChecks()
.AddCheck("startup", check => HealthCheckResult.Healthy(), tags: [ "startup" ])
.AddAzureQueueStorage(tags: [ "runtime" ]);
And the runtime tag would be used to differentiate it upon injection:
app.MapHealthChecks("/ct-healthz/startup", new HealthCheckOptions { Predicate = (check) => check.Tags.Contains("startup") });
app.MapHealthChecks("/ct-healthz/runtime", new HealthCheckOptions { Predicate = (check) => check.Tags.Contains("runtime") });
Liveness probe
Liveness probes can be used to automatically restart a container when the application gets into a failing state. This probe should be used only for those cases where restarting the application can solve a problem - such as by clearing the memory.
The healthchecks used for this probe could be the same as those used for the readiness probe, or they might be different, based on the application's requirements. It is common for the same endpoint to be used but to use different thresholds compared to the readiness probe. For example:
- Readiness probe: an error threshold of 3, with a 2 seconds timeout.
- Liveness probe: an error threshold of 5, with a 5 seconds timeout.
Azure Portal probes configuration
Let's first see how these probes can be configured through the Azure Portal, before moving to doing the configuration through Bicep.
If you open the Container App's Edit and deploy functionality on the Portal, you will see that custom probes are disabled by default:
All three probes configuration follows the same pattern:
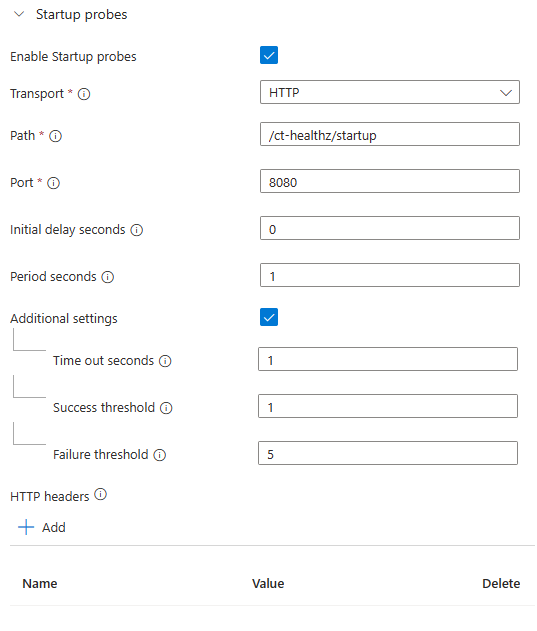
The configuration above can be read as follows: when the container starts, start doing HTTP GET requests to the /ct-healthz/startup endpoint. For each request, give the application 1 second to respond with a success status code. If the response is successful, stop running the probe (as this is a startup probe). If not, continue trying up to 5 times, at which point the container will be considered to have failed.
Do notice that the HTTP port must be the one where the healthchecks functionality is running. Since .NET 8, the default port used for the official ASP.NET Core docker image is 8080.
Bicep probes configuration
Achieving the same configuration defined in the previous section with Bicep is very simple. For example:
resource containerApp 'Microsoft.App/containerApps@2024-03-01' = {
name: 'test'
location: resourceGroup().location
properties: {
// ...
template: {
containers: [
{
// ...
probes: [
{
type: 'Startup'
failureThreshold: 5
initialDelaySeconds: 1
periodSeconds: 1
successThreshold: 1
timeoutSeconds: 1
httpGet: {
port: 8080
path: '/ct-healthz/startup'
}
}
]
}
]
}
}
}
To keep the sample short, the above code skips many of the required properties for a Container App resource.
If you want to learn how to do a full Container App Environment and Container App deployment through Bicep, I have a blog post with a sample source code available here: Microservices with Azure Container Apps and Bicep templates.
Wrapping up
Combining health probes with healthchecks allows you to automate the monitoring and restart of your applications hosted on Container Apps and Azure Kubernetes Service. If you use Application Insights, you can also set up alerts based on the request logs for the failing healthchecks, to have automated notifications.
Bicep projects can (and should) also be treated with CI/CD (Continuous Integration and Continuous Delivery), and if you are interested in doing that with Azure DevOps, see this blog post of mine.